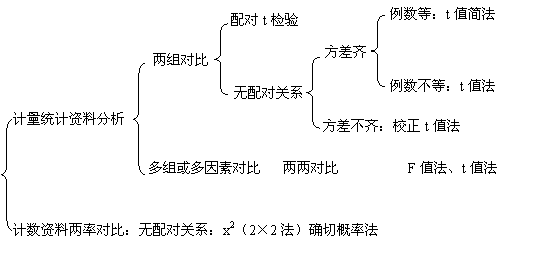
�������� ͳ��ѧ��Ӧ��
һ��ͳ���еļ����������
��.���壨population����������sample����
���������Ǹ����о�Ŀ��ȷ����ͬ�ʹ۲쵥λ��ȫ�塣��ʵ�ʹ����о����Ǵ������г�ȡ������Ŀ������������Ϣ���ƶ����������������Ǵ������������ȡ���ֹ۲쵥λ����ʵ��ֵ�ļ��ϡ���������������ȫ���Ϊ���塣���ö�����ʵ�飬���Զ����ʵ�������粻��֤�����۶��ﷴӦ��һ�£�û���Ա���죬һ���Dz����������Զ���ģ���ʵ�����ʱ���ô��۸���Ķ�����ý��۲����������Զ��
��.���ʣ�probability����
2.1 ��������������¼������Ŀ����Դ�С����ֵ�����ãб�ʾ������¼��ĸ����ڣ��룱֮�䣬�����ܣСܣ�������С����ٷ�����ʾ����Խ�ӽ���������ij�¼������Ŀ�����Խ��Խ�ӽ��ڣ�����ʾij�¼������Ŀ�����ԽС��ͳ���ϵĺܶ���۶��Ǵ��и����Եġ�ϰ���Ͻ��С�0.05����С�0.01����ΪС�����¼�����ʾij�¼������Ŀ����Ժ�С��
2.2 �����������:�����ֳƻ��ʣ��Ƿ�ӳij�¼����������Դ�С�������ڴ��۸����һȺС���У������ȡһֻ�������䲻��Ԥ������ۣ�������ͳ�����ۺ��������ʿ����������ȡ��һֻΪ���ԵĿ�������50%��Ҳ�����۷����ʣ����ʣ�Ϊ0.5��ͬ�����������ȡ���ƾ�Ϊ���Եĸ���Ϊ0.5��0.5=0.25,�������Եõ�����ɣ�����ȡnֻ��Ϊ���Եĸ���Ϊ0.5n��
һ�������������ij�¼��ĸ�����δ֪�ģ�����ֻ��ͨ���������¼��ķ��������ƶϸ��ʡ����Ը���Ҳ������Ϊ���������ظ��۲�ʱij�¼��ķ����ʡ���
���ڴ��ڳ�����ʵ�ʹ����У�����������ġ��ʡ����������ǽӽ������ǵ�ͬ�������ʻ����������ͳ��ѧԭ�������ǿ����������ʻ������������һ����Χ��ʹ�����ʻ�������ڸ÷�Χ�ĸ���Ϊ95%������ǡ�95%�����ޡ�������Խ���ظ�����Խ�࣬95%���������·�ΧԽ�ӽ�����������������ľ��ܶ�Ҳ��Խ����ҩЧͳ�Ʒ����У������á�95%�����ޡ��͡�99%�����ޡ����������������ʻ������Ԥ�ڷ�Χ��
2.3 �����Լ�����������ˮƽ��ҩЧͳ�Ʒ����У�����������������ʣ����бȽ�ʱ�������������IJ����ͳ��ѧ���Ƿ������������壬���ּ��鷽�����ǡ������Լ��顱�������Լ��鷽���ܶ࣬������˼·��һ�µġ�����������������Լ���Ϊ���������£�a.����������в��ʱ�����ֲ����������������������ֱ�������������ͬ�����壬Ҳ�п���ʹ�������ݾ�����ͳһ���壬������������IJ���ֻ�����dz����������ġ�ͳ��ѧ�ϳƺ�һ�����Ϊ����Ч���衱��b.���ݴ���������Ĺ��ɣ������������������ݼ��������Ч���衱�����Ŀ����ԣ����ʣ��ж��ͨ���ô�д��P������ʾ��c.���P<0.05(��5%)��0.01(1%)�Ϳ���Ϊ��������ͬһ����Ŀ����Ժ�С���������Ч���衱��������������IJ����ͳ��ѧ�����������Ե����塣��֮�����P>0.05����ʾ��������ͬһ����Ŀ�����>5%,���Dz���������Ч���衣�������������һ����𣬵�ͳ��ѧ����Ϊ���ֲ����ͳ��ѧ���塣
2.4 ͳ�ƽ��ۼ�רҵ���ۣ�ͳ��ѧ������˵����������ͬһ����Ŀ����ԣ����P��0.05��P��0.01�����ʾ�������Բ�ͬ����Ŀ����ԡ�95%���99%������˵��������������ʣ����ֵ�Ĵ�С��ʵ���ϣ�ͳ��ѧ�ϲ��쳣����ʱ����רҵ������δ�ؾ����������壬��Ϊ��ʱ�����������ֵ�ϵIJ�����ܴܺ�Ҳ���ܲ���ȥͳ�ƽ��۳��С������������dz���������������˵�������롰����������ܴDz�������������ԣ����ڸ��ã���������ͳ��ѧ���������塢�������������������������˵������ǿ��ͳ��ѧ���۵����岻����רҵ���۵�����(��1-11)����Ȼͳ��ѧ������רҵ���۵���Ҫ�ο����ݣ���������Ψһ�ģ����Ͼ�ֻ�Dzο�������������רҵ���ۻ�Ҫ���רҵ֪ʶ������ʵ�����ơ�������ͳ��Dz��ܻ�á�
���ԣ���ҩЧͳ�Ʒ����У�����ȷ����ͳ��ѧ�ĸ��ԭ���ͷ����õ�ͳ��ѧ���ۺ���ȻҪ���ݾ��������ҩ��רҵ֪ʶ���������������о����ۣ���רҵ���ۡ�
����ʵ���������Ĺ��㣺
�����Ͽ���������Ȼ�������壬����Խ��������Ҳ��Ӧ���������Ĵ�������Ȼ����С���������Ӵ��������Ʊ����ӹ�����������ʵ��ɱ������磬��ҩ��רҵΪ��������ʵ����������ϰ���Թ涨��һ������ʵ�����������ڸ�ֵ��
ʵ�鶯��Ļ���������
2.1 С���С�����㡢�ܵȣ���ÿ��10-30�����ڰ�������Ϊ3-5��������ʵ��ʱ��ÿ�鲻����8����
2.2 �еȶ���á�����ȣ���ÿ��8-20����
2.3 �������è����ȣ���ÿ��5-15����
����ʵ����ƵĻ�������
3.1 ʵ����Ƶ�Ҫ�أ��������ء����Զ���ʵ��ЧӦ��
3.2 ʵ����ƵĻ���ԭ��
ʵ��ʵ����ƵĿ�ѧ�ԣ����˶�ʵ����������ء��۲�ָ�����������İ������⣬��������ѭʵ����Ƶ�����ԭ������ԭ���ظ�ԭ�����ԭ��
3.2.1 ����ԭ��
���ö�����Ϊ��ʹ�۲�ָ��ͨ���Աȷ���������仯�������DZȽϵĻ�����Ҫ���пɱ��ԣ��ڱȽϸ���֮�䣬���������ز�ͬ�⣬�����Ǵ������ؾ���������ͬ���Ӷ����ݴ����벻����֮��IJ��죬�˽�����ش���������ЧӦ��ͨ��ʵ��Ӧ����ʵ����Ͷ����顣��������ʵ������ͬ����Ҫ���塣��Ϊ��ʵ���������зǴ������ظ���������綯�������졢ʵ�黷�������õȡ��������һ�������飬Ӧѡ��ͬһ���������ء��Ա�����Ķ����ͬһʵ�黷���½���ʵ�飬�����Dz��������ʵ�鴦��������ʵ�����������ķǴ������ش�����ͬ״̬�����߶Աȿ������ǶԱ����ش�����������۲�ijЩ�����������йص�����Ч��ʱ����������գ������ֱ漲���ĺ�ת��ҩ���Ч�������������ڵ����á�
�����ж�����ʽ���ɸ���ʵ��Ŀ�ĺ����ݼ���ѡ��
��1���հ��գ�����������գ������鲻���κδ������ء���۲�ij��ѹҩ������ʱ��ʵ���鶯����ý�ѹҩ�������鶯�ﲻ����ҩ�����ð�ο�����հ��ռ����У�����������ʵ������������������ϵIJ��죬�Ӷ�Ӱ��ʵ��ЧӦ�IJⶨ��
��2���������գ�������ʵ�����ͬһ���Զ�����С�������ҩǰ����ĶԱȣ�����Aҩ����Bҩ�ĶԱȣ���Ϊ�������ա�
��3������գ��ֳ������ա���ר�����������飬���Ǽ���ʵ����֮������ա������ü���ҩ��ͬʱ����ͬһ�������Ա��⼸��ҩ���Ч������Ϊ����ա�
��4�������գ������������飬ʵ�������ֵ������ֵ���жԱȡ������ҩ����Ч�۲죬����֪��Ч������ҩ����Ϊ�������飬���µ�ʵ�����ҩ��ЧӦ����֪����ҩ�����ý��жԱ�ʵ�顣��Ϊ�ܶ�����²��������κ������Dz�����ҽ�µġ����⣬��������ij���µļ��鷽���Ƿ��ܴ��洫ͳ�������о���
��5����ο�����գ����������һ����ҩ�����õļ�ҩ����Ϊ��ο����placebo��������Ҫ���á����ܹ�������һ��˵����������С��ģ��ʵ���о���
��6��ʵ����գ������鲻ʩ�Ӵ������أ�����ʩ��ij���봦�������йص�ʵ�����ء�
3.2.2 ���ԭ��
��ʵ���о��У�����Ҫ���ж��գ���Ҫ��������˴��������⣬�������ܲ�������ЧӦ�ķǴ�������Ӧ�����ܱ���һ�¡���ѭ�����ԭ��������������Ե�һ����Ҫ�ֶΡ�Ҳ������ͳ�Ʒ���ʱ������ͳ���ƶϵ�ǰ�ᡣ�����ָʵ������ʵ��˳��ͷ����������������������ʹ֮ʵ���������ʵ��������ʱ�����ǵĻ����Ǿ��ȵġ�ͨ���������һ�Ǿ���ʹ��ȡ�������ܹ��������壬���ٳ���������ʹ������������������һ�£���������������Ϊ�����Ӷ�ʹ�������ز�����ЧӦ���ӿۣ����ڵó���ȷ��ʵ�������������һ��ҩ����Ч��ʵ�飬�۲�ij���µĿ��ݿ�ҩ���ʧѪ�ݿ˵�����Ч����ʵ����Ͷ����鸴��ͬһ�̶ȵ�ʧѪ���ݿ�ģ�ͣ�Ȼ�����ʵ�����ݿ���ҩ��������������������ˮ���������ķ��䲻��������У���Ӫ��״̬�ú����׳�Ķ��������ʵ���飬��Ӫ������õĶ��������ˮ�����飬���õ�������ʵ����������������ӳҩ�����Ч���ܿ����Ƕ���������������
������ķ����ܶ࣬�ɲ���������б���������ֱ������У��������ó�ǩ�ķ���������ɲ���ҽѧͳ��ѧ��
3.3.3 �ظ�ԭ��
�ظ���ָ������������������������ʵ�������Ҫ��һ�����������ظ��DZ�֤���н���ɿ�����Ҫ��ʩ������ʵ�鶯��ĸ�������ԭ��һ��ʵ������������ȷʵ�ɿ�����Ҫ����ظ�ʵ�鷽�ܻ�ÿɿ��Ľ�����ظ���������Ҫ�����ã�һ�ǿ��Թ��Ƴ������Ĵ�С����Ϊ������������С���ظ������ɷ��ȡ����ǿ��Ա�֤ʵ��Ŀ��ظ��ԣ��������ԣ���
�ġ�ʵ����ƵĻ�����������ȫ�����ơ������ơ���������ơ�����ʵ����ơ���������ơ�������ơ�
�塢ʵ��ͳ�Ʒ�����
5.1 ��ѧ����
5.2 ���ö�������ͳ�Ʒ����������Լ��飺
5.2.1 ���t���飺
ͬ��Ƚϵ������Լ�����ָͬһ��ʵ�������ҩǰ���������ֻ����顢���ֲ�ͬ����ʱ���۲�ֵ��ֵ�������Բ��顣
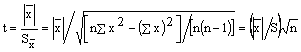 ����������f = n-1��
����������f = n-1��
x![]()
![]() ʽ�У� Ϊ��ֵ�ľ�����S��Ϊ��ֵ����
ʽ�У� Ϊ��ֵ�ľ�����S��Ϊ��ֵ����
����жϣ�t��t0.05����P��0.05���������������壻t<t0.05����P>0.05���������������塣
5.2.2 ����t���飬����Ƚϵ�t���顪������tֵ��
��1������tֵ����ʽ��
![]()
![]()
![]()
���ɶ�f = n1+n2-2
��2����tֵ��ʽ��
����������������ߣ��������϶࣬�ֻ�������ߡ���ʱn1=n2=n��
���Ϲ�ʽ�ɼ�Ϊ��
![]()
���ɶ�f = 2(n-1)
��3��У��tֵ��ʽ����t' �����������鷽����ߣ����������Ƿ���ȣ�
![]()
У�����ɶȣ�![]()
������t���鷨�����������IJ��������������ʱ����Ҫ�����Ϸ��ϳ�̬�ֲ��⣬��Ӧ������ķ�������ƽ����Ҫ���������Ҫ����У��tֵ����
5.3 ��������ͳ�Ʒ���������ѡ��
��������Ҳ�Ƽ������ϣ��ֳ��ʷ�Ӧ���� ���������ϵ������Լ�����������������ʵ�ͳ�Ʒ�������ҩЧͳ�Ʒ����У���Ӧ�������ϵ��ص��磺������Թ�ϵ�����ȼ���ϵ�ȼ�������ͳ�Ʒ�������ѡ��������ѡ���ʵ���ͳ�Ʒ��������������г����������������Լ���һ������������1-12�����ڽ�����Ӽ������ۡ�
�� 1-12 ��������ͳ�Ʒ�������ѡ��
���ɱ���ͬ ��������0��1������2(2��2��)
����Թ�ϵ
��������0��1������ֱ�Ӹ��ʷ���1��
���� ���ɱȲ�ͬ��������������������Ȩ����2����2��
�Ա� �������������ԡ���������������������2��
������ ����Թ�ϵ �������� ���ƶԱ� ������2��
�ϣ��� ������ ��������ʵ����ʶԱȡ�����ά��2��
������ ���ж����ۺ϶Աȡ���������������2��R��C����
�ϣ�ͳ �ȼ���ϵ
�Ʒ��� ���� ���������������Աȡ�������������2(2��2��)
�Ա�
�еȼ���ϵ���������������������������������ȼ���ֵ����3��
*��ֱֵ�Ӹ��ʷ����µļ�����������Fisherֱ�Ӹ��ʷ������Ҳ�ɷֱ�
�������������м�����������2���飻�ȼ���ֵ�����µļ�����������Ridit����
ȫ��ͬ��
5.4 ��������ͳ�Ʒ�����ѡ��
�������ϣ�Ҳ�ɼ������ϣ��ֳ�����Ӧ���ϣ��Ƕ�ÿ���۲�������ij��ָ���
��ֵ��С���õ������ϡ�����Ѫѹֵ��Ѫ��ֵ��Ѫϸ�����ȡ����������ں�����Ϣ��
�������Ϸḻ��ʹҩЧͳ�Ʒ�������õ��������͡�
�������ϵ�ͳ�Ʒ��������������Է�Ϊ�����࣬��������ͳ�ơ�
�͡��Dz���ͳ�ơ���ǰ�߳���Ҫ��һ������ֲ���ǰ�ᣬһ����Ҫ���������ϵķֲ���
�����ϡ���̬�ֲ�������������Ȼ�д���С�����еȾӶ࣬���зֲ��ھ����������ر�
����ر�С�����ݺ��١����ݵķֲ����γ�һ���߷�λ���У��������ڴ���������ȡ�
�ԳƵ��������ߣ���̬���ߣ�����������£�һ��������ݵķֲ�����Ƿ��ϳ�̬����
�ģ��������ͳ�Ʒ�������Ҫ�ij������������ҩЧͳ�Ʒ����У�Ҳ������һЩ����
���ϲ����ϳ�̬�ֻ������ֲ�������ʱ�ֲ��������ȷ��������������£�����ʱ��
��ͨ������ת���ķ���תΪ��̬�ֲ����������ֲ�����Ӧ����Ӧ�ķ��������⣬ͨ��
��ͳ�Ʒ����Ͳ����á���ʱ���÷Dz���ͳ�Ʒ�����
5.4.1 �������ϵĴ����Բ���
5.4.1.1����(��������m����)��������ӳ��һ��������ݵļ������ơ������������ʣ�
�������������ij˻�����ֵ�ܺͣ�n![]() =��x������ֵ�������ֵ֮�ͺ�Ϊ�㦲(x-
=��x������ֵ�������ֵ֮�ͺ�Ϊ�㦲(x-![]() )=0��
)=0��
����ֵ�������ֵ��ƽ���ͼ���(x-![]() )2��Ϊ��Сֵ��
)2��Ϊ��Сֵ��
���ڴ��������Ͼ����ļ��㻹���������Ƽ��㷽�����ȫ������ݷ��ȡ����ڽ���
�����������ձ�ʹ�ã�����ȷ������ļ�������������Ƽ��㲻�ٽ��ܡ�
5.4.1.2 ���S��D����n-1������ʽ����1-37����
�����Ƿ�ӳ����ֵ��ɢ�ԵIJ�������������������ϵ����CV����������
ҩЧ�о��з�ӳʵ����ȶ��ԡ�
5.4.1.3����S![]() ����
����
�����ʾ�������Ĵ�С���Ƿ�ӳ�����ɿ��ԵIJ���������С��˵��������
���С��������������������Ͻӽ�����������������������ܵĿɿ��Խϴ�֮��
�����Խ�����ʾ��������Խ���ɿ������������Ŀɿ��̶ȿ��þ����Ӽ������
��Χ�����ơ���![]() ��S
��S![]() ��Χ�ڣ�����������ֵĸ���ԼΪ70�����ɴ��Ե�˵�ظ�100
��Χ�ڣ�����������ֵĸ���ԼΪ70�����ɴ��Ե�˵�ظ�100
��ʵ�飬�õ�100��������Լ��70��������������Χ�ڡ��ɼ�S![]() ԽС������������
ԽС������������
���������������ΧҲԽС���ɿ��̶ȴ�,�����Ŀ��ų̶�Խ�á�
����ͱ���ͬ��ǰ�߱�ʾ��������ֵ����ɢ�̶ȣ���������˵����������
�ij����������������������������ɢ�̶ȣ����Ա���ɳ�Ϊ�����������ı�
����ɴˣ�![]() ��s�������������
��s�������������![]() ��S
��S![]() �����������;��в�ͬ�ĺ��塣
�����������;��в�ͬ�ĺ��塣
����������ʽ�Ϻ���������Ϊ�ˣ����꽨��һ����![]() ��s����ʾ�������������
��s����ʾ�������������
��ʾ�����ı���ʱ����á�95�������ޡ�����ʽ�����
5.4.1.4 �����ޣ�99%�����Ĺ�ʽ����1-39����ʽ��1-40����
������ʾ��������˵��������������ڿ��ŷ�Χ����ֵ����95%��������Ϊ���ã�
ͨ����ָ���Ŀ�����ָ95%�����ޡ�ʽ��t0.05��t0.01��������ɶ�f��tֵ�����á�
��f��10ʱҲ����������������tֵ��ʽ���㡣
t0.05=1.960+2.376/(f-1.413)��1.96+2.4/(f-1) (1-73)
t0.01=2.576+4.96/(f-1.66)��2.58+4.8/(f-2) (1-74)
�� 1-13 ����tֵ���
���ɶȣ�f�� 5 8 10 15 20 30 40 80 120 ��
![]()
t0.05 2.57 2.31 2.23 2.13 2.09 2.04 2.02 1.99 1.98 1.96
t0.01 4.03 3.36 3.17 2.95 2.84 2.75 2.70 2.64 2.62 2.58
![]()
��t0.05=1.958+2.45/(f-1) (����λС����������f=3����)
5.4.2 �쳣���ݵ�ȡ��
ͨ��ʵ�����õ��������ϣ��ڽ���ͳ�Ʒ���ǰӦ����Ҫ��������ʹ֮ϵͳ����
�������������ڷ��������Դ�����©�����Ͻ��������Ͳ��䣬�Կ����쳣��������
��������ȡ�ᡣ
��ֵ�ر����ر�С���쳣���ݣ�������רҵ֪ʶѰ��ԭ�����ȡ���⣬���ɴ�
ͳ��ѧԭ�������ó�̬�ֲ����ɣ����Ƹ���ֵ���ֵĸ����ж���������ֵ���ֵ�
�����Էdz�С�������Ϊ���쳣���ݡ���ȥ��������ʽϴ���˵���С�����������
�Ŀ����Խϴ�Ӧ�豣�����䲽�����Ƚ������쳣ֵ��x�����������������������
��ڰ������ԭ��ȡ�
�� x����![]() ��3s��Χ�ڣ�x�����ָ��ʴ���3/1000��x�����Գ�����������Щ
��3s��Χ�ڣ�x�����ָ��ʴ���3/1000��x�����Գ�����������Щ
���쳣������Ӧ��ȥ��
�� x����![]() ��3s��Χ�⣬x����4s��Χ�ڣ�x�����ֵĸ���С��3/1000������7/1000
��3s��Χ�⣬x����4s��Χ�ڣ�x�����ֵĸ���С��3/1000������7/1000
�ɽ��רҵ֪ʶ����ȡ�ᡣ
�� x����![]() ��4s��Χ�⣬x�����ָ��ʴ���7/1000Ӧ��ȥ��
��4s��Χ�⣬x�����ָ��ʴ���7/1000Ӧ��ȥ��
Ӧ����һԭ���ǰ�������У�һ�Ǽ�������������̬�ֲ�������nӦ����11��
���磬��12������ʵ�飬������ʵ�����ݼ���õ�����4sΪ12.1��1.1��һ��
�������п����쳣��ֵ6.0�����жϣ�����4s�ķ�ΧΪ7.7~16.5��6.0�ڴ˷�Χ�ڣ���
Ӧ��ȥ�����¼����ֵ�ͱ��
5.4.3 ��������ƫ̬���ж�
�ж�������������ƫ̬��Ҳ���賣̬�ֲ��IJ�������������壬���ּ���Ƚ�
���ӣ��ɲο�ר���������ṩһ�ּ��б��������˵�����㲽�衣
�� �����������������Ϊ6��8��8��8��3��9��9��9��20��n=9�����![]() =9.44
=9.44
s=4.06��
�� ��ߵ����������ֵ��������������ֲ��20���ھ���9.44���ʸ��ھ���
�������Ϊһ�У�nh=1������8�����ݾ�С��9.44���ʵ��ھ����������Ϊ8����nl=8
�ߵ�������ľ���ֵΪ|nh-nl|=|1-8|=7��
�� �������������ֵ��:��ν���ڡ������⡱��ֵ���ݷֲ��ڣ���0.65s��Χ
�����⡣��������0.65s�ķ�ΧΪ6.8~11.2������6��20����λ�ڸ÷�Χ���⣬����
7�����ڸ÷�Χ���ڡ�����no=2��ni=7��������������ľ���ֵΪ| ni-no|=|7-2|=5��
�� �жϣ�|nh-nl|��2������ʾ�����ڶԳ�������ƫ̬��| ni-no|��2������ʾ����
�ڷ岨������ƫ̬��
�ڶԳ����ϻ�岨������һ����ƫ̬ʱ��������Ϊ���Ϸֲ��볣̬�ֲ��IJ��
����������(P��0.05)��
��ȷ��������ƫ̬������£���Ӧ���þ����ͱ���Ƚ���ͳ�Ʒ��衣Ӧ����
����ת������÷Dz���ͳ�Ʒ���
5.4.4 �����Ƿ�Ҫת����
��ҩЧͳ�Ʒ����У�����רҵ֪ʶ�����ϵ����ʣ����轫�۲�ֵ��ת��ΪX��
Ȼ����XΪֱ�Ӽ�������������������������Ϳ����ޣ��������תΪXֵ��
������ת�����о���ЧӦ��Ӧ��ϵ��������С��Ч���������ЧŨ�ȵ�ƽ����
�ǣ���������x������ת����X=�Sx������X�ľ��������ͨ��ȡ��������ת������
��õ�ƽ�����Ƽ���ƽ����G������ֵ��ֱ�Ӽ���ľ�����������ͬ�����Ҫֱ����
x����G�����轫��Щ�۲�ֵ����ٿ�n�η�����G=�S-1���ƩSx/n����ת����������
��
������ת��������DZ���ڡ�Ѫ��ʱ�估ƽ���ٶ�ʱ����������������ת����
X=1/x��������������ת���õ���ƽ������Ϊ���;�����H��������ʽ��1-41����
��ƽ��ת����ƽ����ת��:����������ݻ������ʱ����ʱ�����X=������
X=x2��X=x3��ת��������ͨ��Ҫ�ı����ٵĵ�λ��
�� ����ת������������ת��Ϊ���ʵ�λ����Ӧǿ��ת��Ϊ������ֵ�ȵȣ�
��רҵ���۶�����
��֮����ҩЧѧ�о��У����ݵ�ת���Ǻ��ձ顢�����ģ���ʱ���ǽϸ��ӵġ�
��ת����Ŀ�Ķ���Ϊ�˸��õķ�ӳҩ��ЧӦ�Ĺ��ɺͱ��ʡ�
��������ƫ̬ʱ�����˲��ò���ͳ�Ʒ�������ʱ����������ת���⣬���ɲ���
�Dz���ͳ�Ʒ���
5.4.5 �Dz���ͳ�Ʒ�
�����ڢ�������ƫ̬�ߣ���������ɢ�Ƚϴ۷���룻�ܹ۲�ָ�겻�ܶ����ߣ���ҩЧɸѡ�еij���������
���ڼȿ���һ�㷽���ֿ��÷Dz���������Ӧ�������ó���IJ���ͳ�Ʒ�����ֻ���ڲ��˲��ó���ͳ�Ʒ���������û���ʵ�������ת������ʱ�Ų��÷Dz���ͳ�Ʒ�����
(֣Ң���쾸)